|
|
 @vladforum
@vladforumВход
Здравствуйте, гость ( Вход | Регистрация )



 12.2.2018, 11:13 12.2.2018, 11:13
Сообщение
#1
|
|
 НеЛиберал Возраст: 46 Группа: Пользователи Сообщений: 46 964 Регистрация: 16.9.2002 Из: Владимир Пользователь №: 1 840 Вставить ник Цитата |
В параллельных ветках в модуль добавляются разные функции.
При анализе объединения двух веток прога находит в функциях одинаковые строки и дробит конфликтный блок на части. Соответственно при объединении получается не схема "Блок В + Блок С", а "Блок В(часть 1)+Блок С(часть 1)+общая строка+Блок В(часть 2)+Блок С(часть 2)". Пример: Ветка В Цитата Функция СложитьЗначенияМассива(МассивЧисел) Результат = 0; Для Каждого ЭлементМассива Из МассивЧисел Цикл Результат = Результат + ЭлементМассива; КонецЦикла Возврат Результат; КонецФункции Ветка С Цитата Функция СложитьЗначенияТаблицы(ТаблицаЧисел) Результат = 0; Для Каждого ЭлементаТаблицы Из ТаблицаЧисел Цикл Результат = Результат + ЭлементТаблицы; КонецЦикла Возврат Результат; КонецФункции Что хочется получить на выходе? Цитата Функция СложитьЗначенияМассива(МассивЧисел) Результат = 0; Для Каждого ЭлементМассива Из МассивЧисел Цикл Результат = Результат + ЭлементМассива; КонецЦикла Возврат Результат; КонецФункции Функция СложитьЗначенияТаблицы(ТаблицаЧисел) Результат = 0; Для Каждого ЭлементаТаблицы Из ТаблицаЧисел Цикл Результат = Результат + ЭлементТаблицы; КонецЦикла Возврат Результат; КонецФункции Что позволяет сделать KDiff при решении конфликта? Цитата Функция СложитьЗначенияМассива(МассивЧисел) // из В Функция СложитьЗначенияТаблицы(ТаблицаЧисел) // из C Результат = 0; // общая строка, не вызвала конфликт Для Каждого ЭлементМассива Из МассивЧисел Цикл // из В Результат = Результат + ЭлементМассива; // из В Для Каждого ЭлементаТаблицы Из ТаблицаЧисел Цикл // из C Результат = Результат + ЭлементТаблицы; // из C КонецЦикла // общая строка, не вызвала конфликт Возврат Результат; // общая строка, не вызвала конфликт КонецФункции // общая строка, не вызвала конфликт Можно ли заставить рассматривать как один блок конфликта указанный набор строк, а не брать автооценку KDiff'а, при которой он все дробит на запчасти? Сообщение отредактировал G_Max - 12.2.2018, 11:15 --------------------
20!9
|
 |
 
|



|
| |
 |
Ответов
(1 - 19)
|
12.2.2018, 16:14
Сообщение
#2
|
|
 BLUE LIVES MATTER Возраст: 60 Группа: Пользователи Сообщений: 32 415 Регистрация: 7.8.2001 Из: White Plains, NY Пользователь №: 473 Вставить ник Цитата |
Цитата(G_Max @ 12.2.2018, 4:13)  В параллельных ветках в модуль добавляются разные функции. При анализе объединения двух веток прога находит в функциях одинаковые строки и дробит конфликтный блок на части. Соответственно при объединении получается не схема "Блок В + Блок С", а "Блок В(часть 1)+Блок С(часть 1)+общая строка+Блок В(часть 2)+Блок С(часть 2)". Можно ли заставить рассматривать как один блок конфликта указанный набор строк, а не брать автооценку KDiff'а, при которой он все дробит на запчасти? Насколько я понимаю, - только ручками. У kDiff вроде есть GUI, - там и разрулить конфликт. Все эти merge tools не настолько умные, чтобы понимать где новая версия той же функции (что и происходите в твоем случае), а где две разные функции (то, что ты хочешь). Поэтому только руками с использованием GUI. Если такая ситуация возникает постоянно, то это означает только одно - проблема не с kDiff, а с вашей политикой создания веток (это ж branch?), особенно в ситуации когда между ними есть зависимость (dependency). --------------------
Если я попался Вам навстречу - значит Вам со мной не по пути. instagram.com/cmex13
|
|
|
|
|
12.2.2018, 16:25
Сообщение
#3
|
|
|
НеЛиберал Возраст: 46 Группа: Пользователи Сообщений: 46 964 Регистрация: 16.9.2002 Из: Владимир Пользователь №: 1 840 Вставить ник Цитата |
Цитата(abm @ 12.2.2018, 16:14) Насколько я понимаю, - только ручками. У kDiff вроде есть GUI, - там и разрулить конфликт. Все эти merge tools не настолько умные, чтобы понимать где новая версия той же функции (что и происходите в твоем случае), а где две разные функции (то, что ты хочешь). Поэтому только руками с использованием GUI. GUI как раз не шибко помогает. Руками - да, понятно. Если такая ситуация возникает постоянно, то это означает только одно - проблема не с kDiff, а с вашей политикой создания веток (это ж branch?), особенно в ситуации когда между ними есть зависимость (dependency). Просто, ЕМНИП, SVN еще лет 10 назад при одновременной правке одного файла предлагал вариант последовательного применения этих правок. И 1С своим встроенным склейщиком тоже предлагает последовательную вставку(то есть блоками целиком). А тут вот так... По политике правок я еще обговорю с тем, кто этим рулит... И это не общий репозиториум, а мой собственный ознакомительный. И сразу наткнулся на проблему, с которой раньше как-то не особо сталкивался. Сообщение отредактировал G_Max - 12.2.2018, 16:29 --------------------
20!9
|
|
|
|
|
12.2.2018, 17:32
Сообщение
#4
|
|
|
BLUE LIVES MATTER Возраст: 60 Группа: Пользователи Сообщений: 32 415 Регистрация: 7.8.2001 Из: White Plains, NY Пользователь №: 473 Вставить ник Цитата |
Цитата(G_Max @ 12.2.2018, 9:25) GUI как раз не шибко помогает. Руками - да, понятно. Просто, ЕМНИП, SVN еще лет 10 назад при одновременной правке одного файла предлагал вариант последовательного применения этих правок. И 1С своим встроенным склейщиком тоже предлагает последовательную вставку(то есть блоками целиком). А тут вот так... По политике правок я еще обговорю с тем, кто этим рулит... И это не общий репозиториум, а мой собственный ознакомительный. И сразу наткнулся на проблему, с которой раньше как-то не особо сталкивался. Если вы используете какие-либо системы контроля версий, типа SVN или GIT, то ситуация должна быть сильно проще, потому что они сами ведут т.н. deltafication, т.е. список изменений в каждом файле. Этот список сильно помогает для разрешения merge conflicts. Соответственно, используемый merge tool (kDiff в данном случае), может проявлять гораздо больше интеллекта и почти наверняка отработает твою ситуацию корректно, или с минимальной ручной доводкой. Если же просто тупо две папки синхронизируете, то тут уж "каждый сам себе злобный буратино". Я не совсем понял что значит "GUI не шибко помогает"? Когда я говорил про "ручками", я и имел ввиду этот самый GUI. Тот Mefge Tool, который я использую, рисует три панели (две исходные и одна результат), и каждый несовпадающий блок можно отметить галочкой, соответственно он пойдет в результат. Отметил оба и получил что хотел. Все просто. P.S. Я сам kDiff не использую и в глаза его не видел :) Посмотрел только как оно выглядит. Ну, примерно как и все остальные похожие прибамбасы, хотя и несколько "попугаисто". --------------------
Если я попался Вам навстречу - значит Вам со мной не по пути. instagram.com/cmex13
|
|
|
|
|
12.2.2018, 19:05
Сообщение
#5
|
|
|
НеЛиберал Возраст: 46 Группа: Пользователи Сообщений: 46 964 Регистрация: 16.9.2002 Из: Владимир Пользователь №: 1 840 Вставить ник Цитата |
Цитата(abm @ 12.2.2018, 17:32) Если вы используете какие-либо системы контроля версий, типа SVN или GIT, то ситуация должна быть сильно проще, потому что они сами ведут т.н. deltafication, т.е. список изменений в каждом файле. Этот список сильно помогает для разрешения merge conflicts. Соответственно, используемый merge tool (kDiff в данном случае), может проявлять гораздо больше интеллекта и почти наверняка отработает твою ситуацию корректно, или с минимальной ручной доводкой. GIT и используется. Если же просто тупо две папки синхронизируете, то тут уж "каждый сам себе злобный буратино". Я не совсем понял что значит "GUI не шибко помогает"? Когда я говорил про "ручками", я и имел ввиду этот самый GUI. Тот Mefge Tool, который я использую, рисует три панели (две исходные и одна результат), и каждый несовпадающий блок можно отметить галочкой, соответственно он пойдет в результат. Отметил оба и получил что хотел. Все просто. А проблема объединения в графическом режиме в жестком позиционировании результата объединения в итоговом тексте. То, что я описал выше. Можно последовательно взять и блок B(первая ветка) и блок С(вторая ветка), но если новый блок разбился на части, то получается описанная в начале путаница. Сначала подряд первые части, потом подряд вторые части и т.д. Дальше исключительно ручками в окне результата расставлять по местам. По-крайней мере я не нашел иного варианта пока. --------------------
20!9
|
|
|
|
|
12.2.2018, 19:05
Сообщение
#6
|
|
|
Новенький Возраст: 48 Группа: Пользователи Сообщений: 9 643 Регистрация: 21.4.2003 Из: Владимир Пользователь №: 2 702 Вставить ник Цитата |
Цитата(G_Max @ 12.2.2018, 17:25) Просто, ЕМНИП, SVN еще лет 10 назад при одновременной правке одного файла предлагал вариант последовательного применения этих правок. И 1С своим встроенным склейщиком тоже предлагает последовательную вставку(то есть блоками целиком). А тут вот так... Так это потому, что эти инструменты применяют более топорный алгоритм. А kDiff соответствует современной парадигме изменений и контроля версий, при которой один программист мог исправить пару строк в начале и конце функции, а другой - в середине. Если они не трогали одни и те же строчки - конфликта не возникает. Даже если они умудрились в сумме сделать функцию неработоспособной - это проблема не контроля версий. --------------------
Ну, допустим, про кипятильник я наврал... Но факт остается фактом!
|
|
|
|
|
12.2.2018, 19:12
Сообщение
#7
|
|
|
НеЛиберал Возраст: 46 Группа: Пользователи Сообщений: 46 964 Регистрация: 16.9.2002 Из: Владимир Пользователь №: 1 840 Вставить ник Цитата |
Цитата(Adamos @ 12.2.2018, 19:05) Так это потому, что эти инструменты применяют более топорный алгоритм. Затыка как раз в добавлении разных новых блоков. Понятно, что при попытке одновременно правки уже существующей функции трудно просчитать, какая из версия правильная. Но тут два новых блока. А kDiff соответствует современной парадигме изменений и контроля версий, при которой один программист мог исправить пару строк в начале и конце функции, а другой - в середине. Если они не трогали одни и те же строчки - конфликта не возникает. Даже если они умудрились в сумме сделать функцию неработоспособной - это проблема не контроля версий. Жаль, что аналитика их видит как один и тот же в двух версиях. И еще посмотрю, как он справляется, если в течение правки старой функции добавляется внутри разное количество строк. Почему-то "топорные" алгоритмы в результате срабатывают гибче. На мой взгляд. Сообщение отредактировал G_Max - 12.2.2018, 19:13 --------------------
20!9
|
|
|
|
|
12.2.2018, 19:20
Сообщение
#8
|
|
|
Новенький Возраст: 48 Группа: Пользователи Сообщений: 9 643 Регистрация: 21.4.2003 Из: Владимир Пользователь №: 2 702 Вставить ник Цитата |
Я так понимаю, что у вас все просто заточено именно под "топорную" логику.
Сам последние годы регулярно пользуюсь Meld, логика которого аналогична kDiff, и каких-то неудобств по поводу того, что он три мои исправления в одной функции выделяет в три разные блока, не испытываю. Часто это и есть - разные правки, просто так совпало, что в одной функции. --------------------
Ну, допустим, про кипятильник я наврал... Но факт остается фактом!
|
|
|
|
|
12.2.2018, 19:46
Сообщение
#9
|
|
|
BLUE LIVES MATTER Возраст: 60 Группа: Пользователи Сообщений: 32 415 Регистрация: 7.8.2001 Из: White Plains, NY Пользователь №: 473 Вставить ник Цитата |
Цитата(G_Max @ 12.2.2018, 12:12) Затыка как раз в добавлении разных новых блоков. Понятно, что при попытке одновременно правки уже существующей функции трудно просчитать, какая из версия правильная. Но тут два новых блока. Странно что такое происходит. Как раз GIT и отслеживает изменения в файлах и знает какая строка добавилась новая, какая удалилась, какую отредактировали.Собственно, его коммиты и есть транзакции, показывающие изменения, и уже на основании этих изменений в репозитории строится окончательная версия файла. Не пробовал использовать именно тот Merge Tool, который по умолчанию идет с GITом, если, конечно, в твоем GIT клиенте такое есть. Кстати, а что именно используется в качестве GIT клиента? --------------------
Если я попался Вам навстречу - значит Вам со мной не по пути. instagram.com/cmex13
|
|
|
|
|
12.2.2018, 19:57
Сообщение
#10
|
|
|
НеЛиберал Возраст: 46 Группа: Пользователи Сообщений: 46 964 Регистрация: 16.9.2002 Из: Владимир Пользователь №: 1 840 Вставить ник Цитата |
Цитата(Adamos @ 12.2.2018, 19:20) Я так понимаю, что у вас все просто заточено именно под "топорную" логику. Сам последние годы регулярно пользуюсь Meld, логика которого аналогична kDiff, и каких-то неудобств по поводу того, что он три мои исправления в одной функции выделяет в три разные блока, не испытываю. Часто это и есть - разные правки, просто так совпало, что в одной функции. Вот и пытаюсь понять, в чем топорность предложить либо параллельную(построчную)анализ и клейку, либо последовательную вставку новых блоков. Изначально предполагал, что я что-то упускаю, не знаю функционал. Именно потому, что работу с репозиториями в 1С никогда не считал нормальным. Ну и объединение текстов аналогично. А пока как раз во вроде бы более прогрессивном и гибком GIT+KDiff выходи хуже. Операция параллельного добавления новых функций в один модуль(например в общего назначения) разными программистами - это вообще норма. Ничуть не более редкая ситуация, чем одновременная правка одной функции. А Meld надо глянуть. У меня на "склеиватель" жестких требований нет. Он с GIT работает? Мне главное GIT использовать. Цитата(abm @ 12.2.2018, 19:46) Странно что такое происходит. Как раз GIT и отслеживает изменения в файлах и знает какая строка добавилась новая, какая удалилась, какую отредактировали. Я так понял по логике, что KDiff работает независимо от GIT. Получил файлы на склейку, собрал, отдал.Собственно, его коммиты и есть транзакции, показывающие изменения, и уже на основании этих изменений в репозитории строится окончательная версия файла. Не пробовал использовать именно тот Merge Tool, который по умолчанию идет с GITом, если, конечно, в твоем GIT клиенте такое есть. Кстати, а что именно используется в качестве GIT клиента? В качестве клиента(если ничего в терминах не путаю) использую GIT Extentions. Он как раз KDiff и пользует. Изменения до склейки доходят нормально. Он сравнивает базовый файл с двумя новопришедшими из веток. Сообщение отредактировал G_Max - 12.2.2018, 19:59 --------------------
20!9
|
|
|
|
|
12.2.2018, 20:15
Сообщение
#11
|
|
|
BLUE LIVES MATTER Возраст: 60 Группа: Пользователи Сообщений: 32 415 Регистрация: 7.8.2001 Из: White Plains, NY Пользователь №: 473 Вставить ник Цитата |
Цитата(G_Max @ 12.2.2018, 12:57) Операция параллельного добавления новых функций в один модуль(например в общего назначения) разными программистами - это вообще норма. Ничуть не более редкая ситуация, чем одновременная правка одной функции. А никакой разницы добавление или правка.А как у вас это происходит? Вот есть например ветка А (мастер). Из нее делаются две другие - В и С. В каждой вносятся изменения в один и тот же файл. Что происходите дальше? Ты пытаешься merge B->C? Или В->A и затем C->A? Первый вариант не совсем корректен с концептуальной точки зрения и может приводит в дальнейшем к merge conflicts и обычно требует rebase. Второй - правильный, и обычно отрабатывает такие ситуации без проблем (у меня их на дню несколько раз возникает), никаких merge conflict обычно не бывает. И, кстати, в каком режиме GIT работает (я имею ввиду GIR workflow - не знаю как это по-русски будет)? Цитата(G_Max @ 12.2.2018, 12:57) Я так понял по логике, что KDiff работает независимо от GIT. Получил файлы на склейку, собрал, отдал. Возможно. Тогда в этом и проблема, если он не использует данные из GIT commits, которые, собственно, сильно облегчают жизнь при merge.Цитата В качестве клиента(если ничего в терминах не путаю) использую GIT Extentions. Он как раз KDiff и пользует. Винда? Это, если я ничего не путаю, совсем уж простая и туповатая хрень. Попробуй какой-нибудь SourceTree или GitKraken - у них есть встроенные merge tools. Цитата Изменения до склейки доходят нормально. Он сравнивает базовый файл с двумя новопришедшими из веток. Что-то я не совсем понимаю. Возможно дело в моем непонимании терминологии на русском. Какие такие "новопришедшие" файлы? В репозитории всегда только один файл, соотвествующий текущему branch. Когда ты делаешь merge, оно не должно вытаскивать файлы из другого branch, оно должно использовать данные из GIT Commits в тот branch. Ну т.е. они (новоприбывшие) в каком-то виде где-то существуют, но не до такой же степени, что ты их прямо оба видишь в файловой системе и натравливаешь на них свой kDiff.--------------------
Если я попался Вам навстречу - значит Вам со мной не по пути. instagram.com/cmex13
|
|
|
|
|
12.2.2018, 20:38
Сообщение
#12
|
|
|
Новенький Возраст: 48 Группа: Пользователи Сообщений: 9 643 Регистрация: 21.4.2003 Из: Владимир Пользователь №: 2 702 Вставить ник Цитата |
Цитата(G_Max @ 12.2.2018, 20:57) А Meld надо глянуть. У меня на "склеиватель" жестких требований нет. Он с GIT работает? Мне главное GIT использовать. Нет, сравнивает только реальные папки и файлы. --------------------
Ну, допустим, про кипятильник я наврал... Но факт остается фактом!
|
|
|
|
|
12.2.2018, 21:18
Сообщение
#13
|
|
|
BLUE LIVES MATTER Возраст: 60 Группа: Пользователи Сообщений: 32 415 Регистрация: 7.8.2001 Из: White Plains, NY Пользователь №: 473 Вставить ник Цитата |
Цитата(Adamos @ 12.2.2018, 13:38) Нет, сравнивает только реальные папки и файлы. Что-то я не пойму никак. У меня такое ощущение, что ТС делает чек-аут веток B и C в какие-то отдельные локальные папки и уже потом использует kDiff для их объединения, тупо натравливая его на конкретные файлы в разных папках. Неудивительно что в этом случае оно будет грохаться вдребезги напополам. Если это так - то в этом и проблема. --------------------
Если я попался Вам навстречу - значит Вам со мной не по пути. instagram.com/cmex13
|
|
|
|
|
12.2.2018, 21:51
Сообщение
#14
|
|
|
НеЛиберал Возраст: 46 Группа: Пользователи Сообщений: 46 964 Регистрация: 16.9.2002 Из: Владимир Пользователь №: 1 840 Вставить ник Цитата |
Цитата(abm @ 12.2.2018, 20:15) А как у вас это происходит? При склейке веток происходит одновременно попытка сделать В->A и C->A, потому что сравнивает он обе ветки с базой. Вот есть например ветка А (мастер). Из нее делаются две другие - В и С. В каждой вносятся изменения в один и тот же файл. Что происходите дальше? Ты пытаешься merge B->C? Или В->A и затем C->A? Первый вариант не совсем корректен с концептуальной точки зрения и может приводит в дальнейшем к merge conflicts и обычно требует rebase. Второй - правильный, и обычно отрабатывает такие ситуации без проблем (у меня их на дню несколько раз возникает), никаких merge conflict обычно не бывает. Но фактически в клиенте команда дается или В->C, или C->B. Цитата(abm @ 12.2.2018, 20:15) И, кстати, в каком режиме GIT работает (я имею ввиду GIR workflow - не знаю как это по-русски будет)? Насколько я понимаю - да. Цитата(abm @ 12.2.2018, 20:15) Возможно. Тогда в этом и проблема, если он не использует данные из GIT commits, которые, собственно, сильно облегчают жизнь при merge. Думаю, проблема все же в том, что надо несколько иначе планировать изменения. Чисто в ветках, не трогая в это время в основной ветке те же самые данные. А потом на нее поочередно делать merge. Цитата(abm @ 12.2.2018, 20:15) Винда? Это, если я ничего не путаю, совсем уж простая и туповатая хрень. Попробуй какой-нибудь SourceTree или GitKraken - у них есть встроенные merge tools. Посмотрю, конечно. Цитата(abm @ 12.2.2018, 20:15) Что-то я не совсем понимаю. Возможно дело в моем непонимании терминологии на русском. Какие такие "новопришедшие" файлы? В репозитории всегда только один файл, соотвествующий текущему branch. Когда ты делаешь merge, оно не должно вытаскивать файлы из другого branch, оно должно использовать данные из GIT Commits в тот branch. Ну т.е. они (новоприбывшие) в каком-то виде где-то существуют, но не до такой же степени, что ты их прямо оба видишь в файловой системе и натравливаешь на них свой kDiff. Все так, но в момент сравнения он сопоставляет 3 файла, собранных из текущего и коммитов. Ведь KDiff всего лишь получает три файла и сравнивает. Цитата(abm @ 12.2.2018, 21:18) Что-то я не пойму никак. У меня такое ощущение, что ТС делает чек-аут веток B и C в какие-то отдельные локальные папки и уже потом использует kDiff для их объединения, тупо натравливая его на конкретные файлы в разных папках. Нет, это за меня делает клиент. Завтра посмотрю, какие параметры/команды клиент засылает в KDiff. Он вызывает консольное окно в одном из вариантов вызова. Неудивительно что в этом случае оно будет грохаться вдребезги напополам. Если это так - то в этом и проблема. --------------------
20!9
|
|
|
|
|
12.2.2018, 22:08
Сообщение
#15
|
|
 дауншифтер Возраст: 41 Группа: Пользователи Сообщений: 4 876 Регистрация: 22.4.2001 Пользователь №: 221 Вставить ник Цитата |
Цитата(G_Max @ 12.2.2018, 21:51) При склейке веток происходит одновременно попытка сделать В->A и C->A, потому что сравнивает он обе ветки с базой. Но фактически в клиенте команда дается или В->C, или C->B. А почему одновременно то? Это как? Обычно сначала мерджится одна ветка, потом другая. Если одновременно то какая-то фигня может получиться (она и получается, видимо). --------------------
«Мы имеем дело не с законами природы, а с нашим представлением о них» Вернер Карл фон Гейзенберг
|
|
|
|

|
12.2.2018, 22:18
Сообщение
#16
|
|
|
BLUE LIVES MATTER Возраст: 60 Группа: Пользователи Сообщений: 32 415 Регистрация: 7.8.2001 Из: White Plains, NY Пользователь №: 473 Вставить ник Цитата |
Цитата(G_Max @ 12.2.2018, 14:51) Все так, но в момент сравнения он сопоставляет 3 файла, собранных из текущего и коммитов. Ведь KDiff всего лишь получает три файла и сравнивает. Это как-то совсем уж вычурно (это я еще слово подобрал мягкое). Почему не делать обычный merge в репозитории? Или GIT Extensions этого не позволяет?Неудивительно что оно не работает как ожидается. Цитата Насколько я понимаю - да. "Да" - что? Там несколько разных вариантов организации workflow. Я спросил какой именно вы используете.Вы меня совсем запутали :) Что именно с чем сравнивается. Правильный вариант - переключаемся в ветку С, делаем pull. Переключаемся в ветку B, делаем pull. Дальше, в зависимости от того, что с чем комбинировать и куда закидывать - оставаясь в текущем бранче B, сделать merge from branch C. В этот момент файла, соответствующего его состоянию в бренче С, на диске _не существует_. Я так понял что есть репо с веткой В, ты делаешь чек-аут ветки С в отдельную папку а потом напускаешь на них kDiff - это неправильно. --------------------
Если я попался Вам навстречу - значит Вам со мной не по пути. instagram.com/cmex13
|
|
|
|
|
12.2.2018, 22:36
Сообщение
#17
|
|
|
НеЛиберал Возраст: 46 Группа: Пользователи Сообщений: 46 964 Регистрация: 16.9.2002 Из: Владимир Пользователь №: 1 840 Вставить ник Цитата |
Цитата(abm @ 12.2.2018, 22:18) "Да" - что? Там несколько разных вариантов организации workflow. Я спросил какой именно вы используете. А вот тут пока я серьезно плаваю. Так что не отвечу. Вы меня совсем запутали :) Что именно с чем сравнивается. Ниже скинул простенькую схему. Чисто один локальный репозиторий. Один файл, куда последовательно добавлял куски кода. Вот что получается в GIT Ext 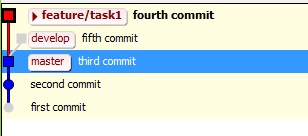 При попытке завершить feature или сделать слив веток feature и develop получаем merge conflict KDiff пытается клеить. 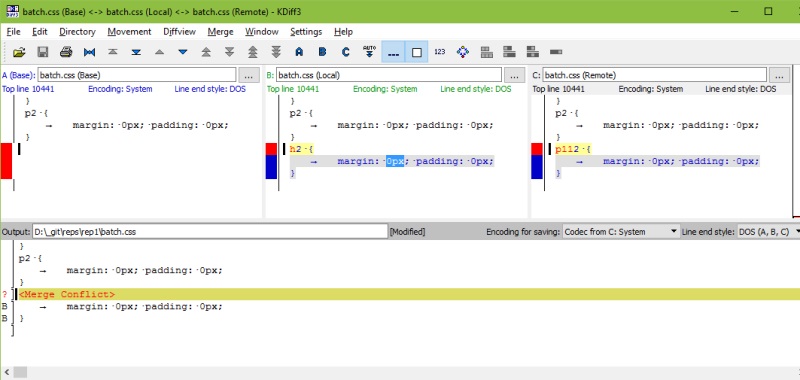 Сообщение отредактировал G_Max - 12.2.2018, 22:38 --------------------
20!9
|
|
|
|
|
13.2.2018, 0:20
Сообщение
#18
|
|
|
НеЛиберал Возраст: 46 Группа: Пользователи Сообщений: 46 964 Регистрация: 16.9.2002 Из: Владимир Пользователь №: 1 840 Вставить ник Цитата |
Буду завтра еще курить рекомендации по созданию тех самых workflow.
--------------------
20!9
|
|
|
|
|
13.2.2018, 2:12
Сообщение
#19
|
|
|
BLUE LIVES MATTER Возраст: 60 Группа: Пользователи Сообщений: 32 415 Регистрация: 7.8.2001 Из: White Plains, NY Пользователь №: 473 Вставить ник Цитата |
Цитата(G_Max @ 12.2.2018, 17:20) Буду завтра еще курить рекомендации по созданию тех самых workflow. К твоей проблеме оно почти не имеет отношения. Если только так, для общего развития.Скорее всего у вас самый простой вариант - Centralized Workflow, он фактически идентичен SVN, самый простенький. Есть еще Feature branching, GitFlow workflow, и Forking workflow. Выбор подходящего зависит, в основном, от того, как у вас организован процесс выпуска релизов и, частично, от организации процесса разработки. Вот как раз в Centralized такое как у тебя и может быть. Чтобы избежать, надо сделать сначала fetch\pull и rebase из удаленного (С). А уж потом накатывать свои изменения (В). Скорее всего поможет, хотя я не уверен. Посмотри вот здесь https://www.atlassian.com/git/tutorials/comparing-workflows если с английским знаком. Там есть пример как раз такой ситуации, что и у тебя, насколько я вижу, для случая с Centralized Workflow. GitFlow и ForkFlow тебе вряд ли нужен, судя по всему, а Feature Branching может помочь, но не в этом случае, когда изменяется один и тот же файл. Вернее, будет меньше merge conflicts. А так, тебе бы нужен другой merge tool, который позволяет добавлять оба блока (и из В и из С) в результат. Но все равно ручками в GUI елозить :) --------------------
Если я попался Вам навстречу - значит Вам со мной не по пути. instagram.com/cmex13
|
|
|
|
|
13.2.2018, 8:24
Сообщение
#20
|
|
|
НеЛиберал Возраст: 46 Группа: Пользователи Сообщений: 46 964 Регистрация: 16.9.2002 Из: Владимир Пользователь №: 1 840 Вставить ник Цитата |
Цитата(abm @ 13.2.2018, 2:12) К твоей проблеме оно почти не имеет отношения. Если только так, для общего развития. Да, спасибо, буду все, что в этой теме предложили курить и пробовать. Скорее всего у вас самый простой вариант - Centralized Workflow, он фактически идентичен SVN, самый простенький. Есть еще Feature branching, GitFlow workflow, и Forking workflow. Выбор подходящего зависит, в основном, от того, как у вас организован процесс выпуска релизов и, частично, от организации процесса разработки. Вот как раз в Centralized такое как у тебя и может быть. Чтобы избежать, надо сделать сначала fetch\pull и rebase из удаленного (С). А уж потом накатывать свои изменения (В). Скорее всего поможет, хотя я не уверен. Посмотри вот здесь https://www.atlassian.com/git/tutorials/comparing-workflows если с английским знаком. Там есть пример как раз такой ситуации, что и у тебя, насколько я вижу, для случая с Centralized Workflow. GitFlow и ForkFlow тебе вряд ли нужен, судя по всему, а Feature Branching может помочь, но не в этом случае, когда изменяется один и тот же файл. Вернее, будет меньше merge conflicts. А так, тебе бы нужен другой merge tool, который позволяет добавлять оба блока (и из В и из С) в результат. Но все равно ручками в GUI елозить :) В организации будет скорее всего использоваться GitFlow(если этот вариант жестко завязан на использование плагина GitFlow). Если полноценная схема работы с удаленным репозиторием избавит от таких конфликтов, будет только хорошо. Сообщение отредактировал G_Max - 13.2.2018, 8:27 --------------------
20!9
|
|
|
|
 |
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0

|
|
Легкая версия |